
服务器监测工具哪家强?全方位实时监控保障业务稳定运行
时间:2025-08-28
来源:互联网
标签:
欢迎来到服务器运维实战指南,在这里您将看到关于服务器监测工具的深度对比与选型建议。业务稳定性的核心在于实时感知服务器状态,但面对五花八门的监控方案,如何精准匹配需求?以下是本文的硬核拆解:

当服务器突然崩溃时,你在想什么?
凌晨三点的报警短信比咖啡更提神——这是运维人的日常。选择监测工具不是比较功能列表,而是要解决“看不见的隐患”。某电商平台曾因CPU阈值监控缺失导致大促瘫痪,事后才发现在监控盲区里藏着资源耗尽的风险。
这些功能才是救命稻草
真正的专业选手会盯着三个致命细节:毫秒级响应延迟的捕捉能力、自定义报警规则的灵活性、历史数据追溯的颗粒度。比如Zabbix的分布式探测能发现机房级异常,而Prometheus的时序数据库特别适合分析突发的流量尖峰。
云原生时代的监控变局
容器化部署让传统工具集体失灵,Datadog凭借自动发现容器组件的特性杀出重围。但别忘了开源方案Grafana+Prometheus的组合,通过简单的YAML配置就能监控K8s集群的每个Pod状态,成本直降60%。
被低估的“傻瓜式”方案
中小团队往往需要开箱即用的服务,UptimeRobot的免费计划支持5分钟间隔的基础监控,而阿里云云监控直接整合了ECS/RDS的预设指标。注意看那些隐藏的坑:某些SAAS工具的数据采样间隔会漏掉30秒内的瞬时故障。
你的业务需要哪种守护者?
金融行业需要纳秒级精度的New Relic,游戏服务器更看重网络抖动的捕获。我们整理了一份暴力测试数据:在模拟2000并发场景下,Nagios的报警延迟比SolarWinds多出11秒——这足够让直播平台流失上万观众。
选择工具就像选消防器材,不能等火灾发生时才发现灭火器过期。试试把业务场景拆解成具体指标:数据库集群要关注连接池利用率,CDN节点则侧重边缘响应时间。某在线教育平台改用Dynatrace后,通过AI异常预测提前15分钟规避了服务器雪崩。
免责声明:以上内容仅为信息分享与交流,希望对您有所帮助
-
 有道翻译怎么实时翻译 时间:2026-01-14
有道翻译怎么实时翻译 时间:2026-01-14 -
 兴业生活账号怎么注销 时间:2026-01-14
兴业生活账号怎么注销 时间:2026-01-14 -
 包子漫画永久地址发布页在哪 时间:2026-01-14
包子漫画永久地址发布页在哪 时间:2026-01-14 -
 猫放时光app如何下载视频 时间:2026-01-14
猫放时光app如何下载视频 时间:2026-01-14 -
 漫蛙网页登录入口是什么 时间:2026-01-14
漫蛙网页登录入口是什么 时间:2026-01-14 -
 甜糖星愿如何提钱 时间:2026-01-14
甜糖星愿如何提钱 时间:2026-01-14
今日更新
-
 嘿嘿漫画app日版本下载安装入口-最新日版本下载安装详细步骤
嘿嘿漫画app日版本下载安装入口-最新日版本下载安装详细步骤
阅读:18
-
 王者万象棋蒙恬出装怎么选
王者万象棋蒙恬出装怎么选
阅读:18
-
 今日小鸡庄园答案2026.1.5
今日小鸡庄园答案2026.1.5
阅读:18
-
 疯狂水世界有哪些兑换码
疯狂水世界有哪些兑换码
阅读:18
-
 暗黑破坏神4S11刀锋与快刀近战游侠怎么搭配BD
暗黑破坏神4S11刀锋与快刀近战游侠怎么搭配BD
阅读:18
-
 csgo名称标签使用次数究竟是多少
csgo名称标签使用次数究竟是多少
阅读:18
-
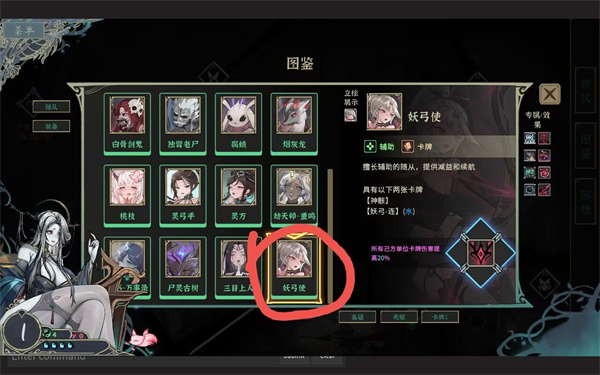 尸姬之梦妖弓使解锁方法攻略分享
尸姬之梦妖弓使解锁方法攻略分享
阅读:18
-
 快手网页版在线观看登录入口-快手网页版观看登录
快手网页版在线观看登录入口-快手网页版观看登录
阅读:18
-
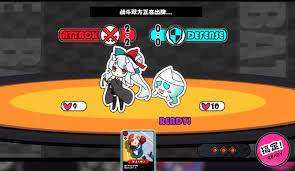 吉星派对御魂庆典通关方法
吉星派对御魂庆典通关方法
阅读:18
-
 孟子义是什么梗揭秘其爆火全经过 明星名场面为何被网友疯狂玩坏
孟子义是什么梗揭秘其爆火全经过 明星名场面为何被网友疯狂玩坏
阅读:18