
网站数据采集实战教程:快速掌握高效方法与技巧
时间:2025-09-05
来源:互联网
标签:
欢迎来到数据采集实战专区,在这里您将看到关于网站数据采集的核心技巧与避坑指南。从基础工具选择到高级反反爬策略,这篇教程会手把手带您突破信息抓取瓶颈,让数据获取效率提升300%。以下是本文精彩内容:

为什么你的采集脚本总被ban?
多数人一上来就猛怼Requests库,结果IP秒进黑名单。试试用异步采集配合UserAgent轮换,像Scrapy-Redis这种分布式框架能让你的请求看起来像真实用户行为。记住:目标网站的风控系统比你想的聪明——某电商平台甚至会检测鼠标移动轨迹。
动态加载数据的破解之道
当你发现BeautifulSoup抓不到数据时,别急着放弃。那些通过Ajax加载的内容,用Selenium+Puppeteer组合能直接模拟浏览器操作。有个取巧的方法:先抓包分析XHR接口,有时候后端API根本没有加密,直接请求反而比渲染整个页面快10倍。
被忽略的存储优化技巧
很多人把数据堆在CSV里就以为完事了。试试用MongoDB存储非结构化数据,它的BSON格式特别适合处理网页采集中的不规则字段。有个真实案例:把200万条商品评价存入MySQL花了3小时,改用MongoDB分片集群后只要17分钟。
反爬虫的七种武器
从简单的验证码到复杂的指纹识别,现在网站防御手段越来越刁钻。但总有破解之法:对于Cloudflare防护的站点,用cloudscraper库可以绕过5秒盾;遇到滑块验证码时,第三方打码平台成本低至0.3元/次。关键是要学会逆向思维——看看对方到底在检测什么。
效率翻倍的冷门工具
除了老牌的Scrapy,现代采集工具正在迭代。Playwright支持多语言自动录制操作,Octoparse的无代码可视化采集适合运营人员。最近发现个神器:Apify能把整个采集流程打包成Docker容器,连调度服务器都省了。
法律红线千万别踩
去年有公司因爬取简历数据被罚200万。采集前务必检查robots.txt协议,注意欧盟GDPR要求的个人数据保护。有个实用建议:在代码里加入访问频率控制和数据脱敏模块,这既是技术优化也是法律防护。
免责声明:以上内容仅为信息分享与交流,希望对您有所帮助
-
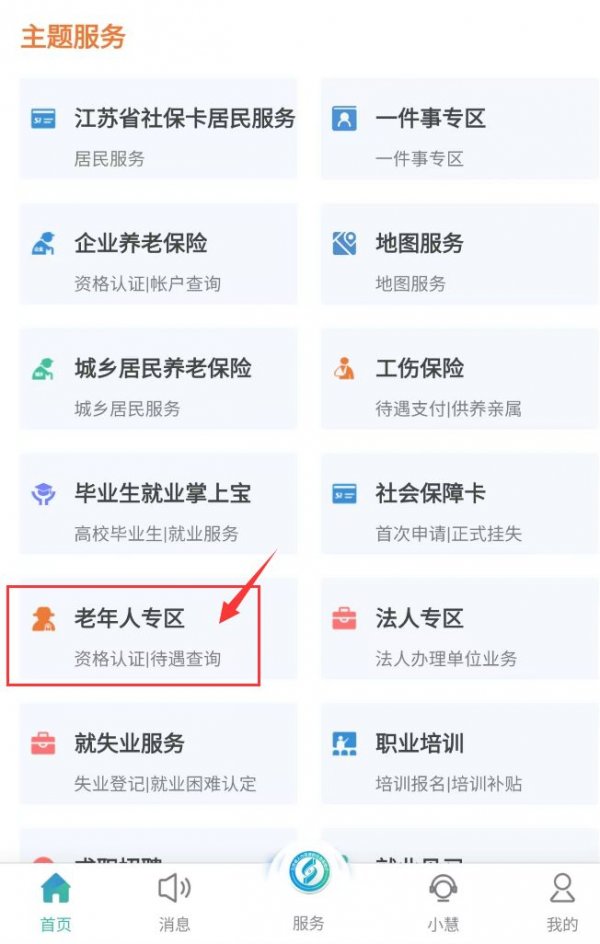 江苏智慧人社退休人员认证如何操作 江苏智慧人社退休人员认证方法 时间:2026-01-16
江苏智慧人社退休人员认证如何操作 江苏智慧人社退休人员认证方法 时间:2026-01-16 -
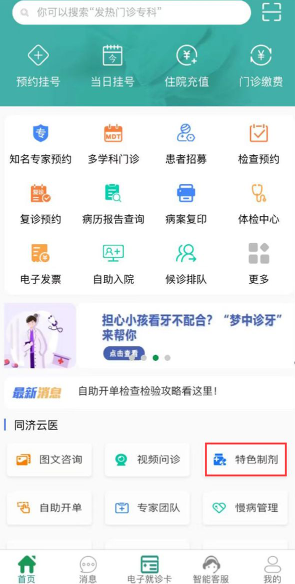 掌上同济app怎么买药 掌上同济买药流程 时间:2026-01-16
掌上同济app怎么买药 掌上同济买药流程 时间:2026-01-16 -
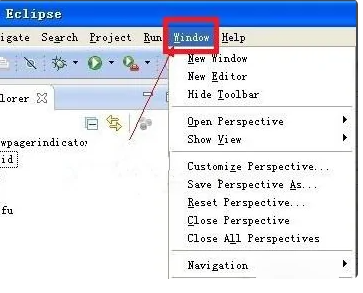 eclipse怎么调大字体 时间:2026-01-16
eclipse怎么调大字体 时间:2026-01-16 -
 中国电信翼支付怎么转人工服务 翼支付在线联系客服方法 时间:2026-01-16
中国电信翼支付怎么转人工服务 翼支付在线联系客服方法 时间:2026-01-16 -
 华为应用商店切换账号详细步骤 时间:2026-01-16
华为应用商店切换账号详细步骤 时间:2026-01-16 -
 抖音查看删除的聊天记录方法步骤 时间:2026-01-16
抖音查看删除的聊天记录方法步骤 时间:2026-01-16
今日更新
-
 谜漫画官网app下载入口安卓版 - 谜漫画官网app下载最新地址链接官方正版
谜漫画官网app下载入口安卓版 - 谜漫画官网app下载最新地址链接官方正版
阅读:18
-
 蚂蚁庄园今日答案(每日更新)2026年1月17日
蚂蚁庄园今日答案(每日更新)2026年1月17日
阅读:18
-
 眉毛的梗是什么梗?揭秘全网爆火表情包背后的搞笑真相!
眉毛的梗是什么梗?揭秘全网爆火表情包背后的搞笑真相!
阅读:18
-
 免费看漫画的软件-无会员漫画app
免费看漫画的软件-无会员漫画app
阅读:18
-
 梦幻西游网页版一键登录-梦幻西游网页版官方入口
梦幻西游网页版一键登录-梦幻西游网页版官方入口
阅读:18
-
 将大禹尊为保护神的民族 蚂蚁新村1月13日答案最新
将大禹尊为保护神的民族 蚂蚁新村1月13日答案最新
阅读:18
-
 百度搜题网页版直达-百度搜题网页版一键使用
百度搜题网页版直达-百度搜题网页版一键使用
阅读:18
-
 快对作业网页版一键使用-快对作业官网直达入口
快对作业网页版一键使用-快对作业官网直达入口
阅读:18
-
 千牛网页版一键登录-千牛官网登录全指南
千牛网页版一键登录-千牛官网登录全指南
阅读:18
-
 哪种海洋生态系统被誉为海洋生物的"幼儿园" 神奇海洋1月13日答案
哪种海洋生态系统被誉为海洋生物的"幼儿园" 神奇海洋1月13日答案
阅读:18