
正则表达式的一点应用
时间:2010-12-18
来源:互联网
- # -*- coding: utf-8 -*-
- '''
- Filename: searchfile.py
- Discription: 搜索指定目录下的网页文件,并从文件中提取title
- By: whitefirer
-
- '''
-
- '''
- 要注意的是:
- 1. 现在的记录方式是追加方式,如果要用覆盖方式,请自行用logo记录,然后一次写入(似乎它只能一次)
- 2. 复制网页文件到指定路径下的功能已注释,如有需要,请自行修改
- 3. 现写了的网页格式有'html', 'mht', 'jsp', 'htm', 'php', 'shtml', 'asp',如有需要,请自行添加
- 4. ....
- '''
- import os, sys, re, shutil, binascii
- startpath = "G:\\Python25" #被操作的文件夹
- targetpath = "G:\\test\\" #复制文件的目的路径
- logopath = "G:\\test\\logo.txt" #提取title存入的文件
- g_wap_pattern = ['html', 'mht', 'jsp', 'htm', 'php', 'shtml', 'asp', 'xhtml', 'aspx']
- #各种网页格式
- #logo = ["logo:\r\n"]
- #以上写在这里只是为了便于修改,如果有需要,也可以写成管道方式或其它方式
- '''
- def ansymhttitle(string): #不能得到非汉字,并且做复杂了
- strinfo = re.compile(r'=..')
- strlist = strinfo.findall(string)
- string = ''
-
- for i in range(0, len(strlist)):
- strlist[i] = hex(int(strlist[i].replace('=', '') , 16)).replace('0x', '') # 多此一举
- string = string + binascii.a2b_hex(strlist[i])
- return string
- '''
- def ansymhttitle(string):
- string = string.replace('=\n', '') #去除'=\n' 也可以换成\n
- strinfo = re.compile(r'=\w\w|=\s')#r'=..' # 匹配字母与数字
- strlist = strinfo.findall(string)
- #print strlist #测试时用
-
- for i in range(0, len(strlist)):
- string = string.replace(strlist[i], binascii.a2b_hex(strlist[i].replace('=', '')))
- return string #替换为相应ascii码后返回
-
- def gettitle(url, waptype):
- file_object = open(url) #开打文件
- try:
- content = file_object.read( ) #读取文件内容
-
- title = re.findall(r"<title>([\s\S]*?)</title>", content, re.M)
- #意思是取<title></title>间的任意多的所有字符\s是空白字符\S是非空白字符
- #r"<title>\s*(.*?)\s*</title>", 这个不对换行进行判断,现在的可以
- #titlepattern = re.compile(r"<TITLE>[...]</TITLE>")
- #title = titlepattern.search(content);
-
- if(title):
- if '' == title[0]:
- title[0] = '无标题' #找到为空时,无标题
- else:
- title = re.findall(r"<TITLE>([\s\S]*?)</TITLE>", content, re.M)
- if title: #上面对大写的<TITLE>标签进行判断
- if '' == title[0]:
- title[0] = '无标题' #找到为空时,无标题
- else:
- title.append('无标题') #未找到时,无标题
-
- if not cmp(waptype, "mht"): #如果是mht文件,则对其title解码
- title[0] = ansymhttitle(title[0])
-
- title[0] = title[0].replace('\n', '') #去掉换行符(主要针对<title>后面的)
- print title[0]
-
- finally:
- file_object.close( ) #关闭文件
-
- lastpath = re.findall(r"\\([\s\S]*?)\\", url, re.M)
- n = len(lastpath) - 1
- #logo.append("http://" + lastpath[n] + "/" + "\t" + title[0] + "\n")
- logostr = "http://" + lastpath[n] + "/" + "\t" + title[0] + "\n"
-
- file_logo = file(logopath, 'a') #以追加方式打开
- try:
- file_logo.write(logostr) #写入信息
- except IOError:
- print('IOError')
- #finally:
- #file_logo.colse()
-
- def searchfile(n, dirname):
-
- for basename in os.listdir(dirname):
- path = os.path.join(dirname, basename) #得到路径下所有的文件的完整路径
-
- if os.path.isdir(path):
- searchfile(n + 1, path) #递归搜索文件
- else:
- #pattern = re.compile(r'(.*?).html') #r'(.*?).txt'
- #if pattern.match(basename):
- #print basename
- if not os.path.getsize(path): #判断文件的大小,如果为空则不执行下面的代码
- continue
-
- for i in range(0, len(g_wap_pattern)):
- if path.lower().endswith(g_wap_pattern[i]):
- print '文件路径:' + path #当是网页文件后缀时打印路径
- #shutil.copyfile(path, targetpath + basename)
- #拷贝文件到目标地
- gettitle(path, g_wap_pattern[i])#得到该网页的title
- break
-
- if __name__ == "__main__" :
- try :
- searchfile(1, startpath) #递归搜索指定路径下的文件
- '''
- print logo
- print len(logo)
- file_logo = open("G:\\test\\logo.txt", 'w')
- try:
- for i int range( 0, len(logo)):
- file_logo.write(logo[i])
- except IOError:
- print('IOError')
- finally:
- file_logo.colse()
- '''
- except:
- print "execute search file fun error"
- raw_input('Enter to continue...') #暂停
作者: whitefirer 发布时间: 2010-12-18
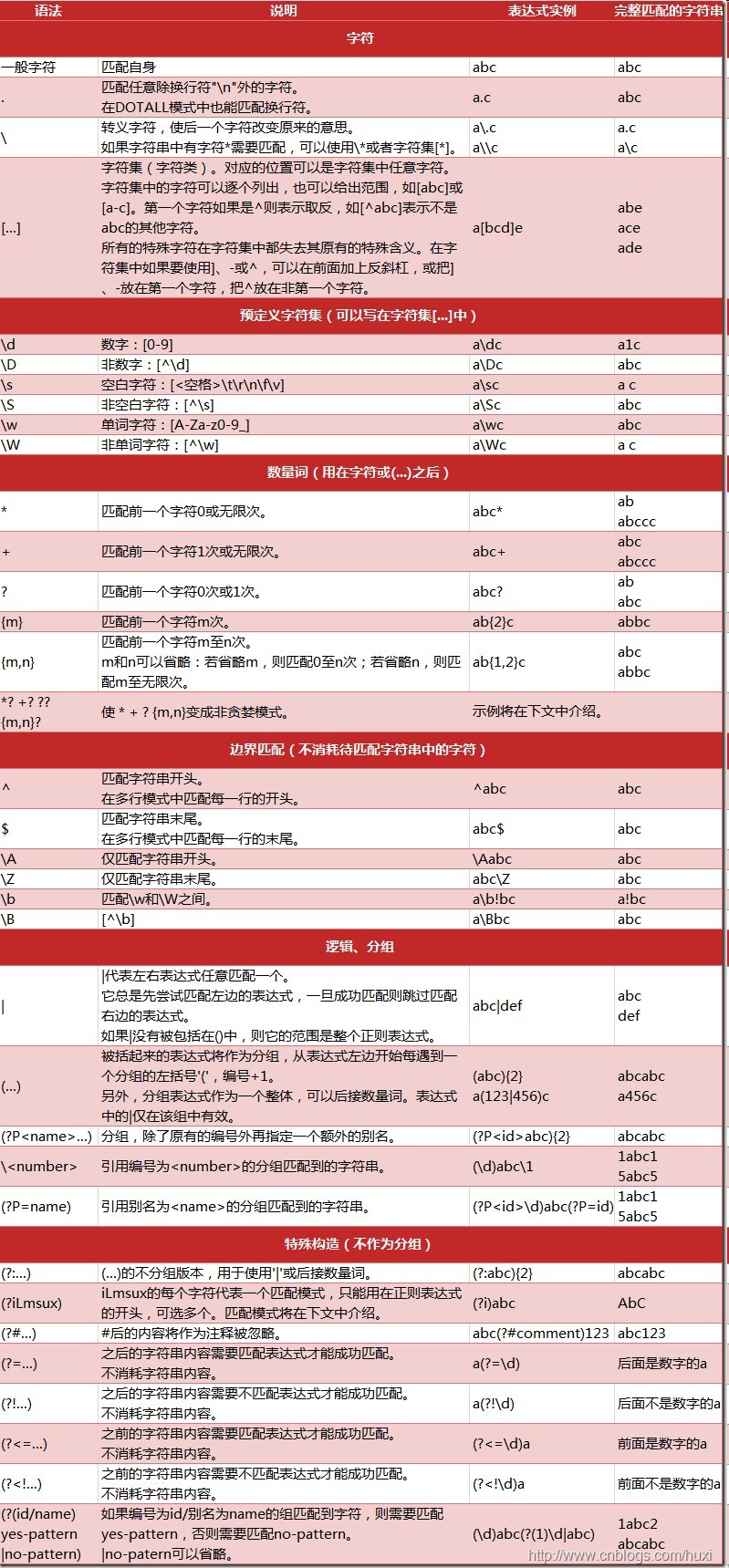
很荣幸在这里看到我写的表格 
作者: ixuh 发布时间: 2010-12-18
相关阅读 更多
热门阅读
-
 office 2019专业增强版最新2021版激活秘钥/序列号/激活码推荐 附激活工具
office 2019专业增强版最新2021版激活秘钥/序列号/激活码推荐 附激活工具
阅读:74
-
 如何安装mysql8.0
如何安装mysql8.0
阅读:31
-
 Word快速设置标题样式步骤详解
Word快速设置标题样式步骤详解
阅读:28
-
 20+道必知必会的Vue面试题(附答案解析)
20+道必知必会的Vue面试题(附答案解析)
阅读:37
-
 HTML如何制作表单
HTML如何制作表单
阅读:22
-
 百词斩可以改天数吗?当然可以,4个步骤轻松修改天数!
百词斩可以改天数吗?当然可以,4个步骤轻松修改天数!
阅读:31
-
 ET文件格式和XLS格式文件之间如何转化?
ET文件格式和XLS格式文件之间如何转化?
阅读:24
-
 react和vue的区别及优缺点是什么
react和vue的区别及优缺点是什么
阅读:121
-
 支付宝人脸识别如何关闭?
支付宝人脸识别如何关闭?
阅读:21
-
 腾讯微云怎么修改照片或视频备份路径?
腾讯微云怎么修改照片或视频备份路径?
阅读:28