
PERL深入探讨--内存管理[1]【原创】
时间:2010-10-08
来源:互联网
本帖最后由 toniz 于 2010-10-08 16:56 编辑
之前遇到过这样一个问题:
Perl数组的存放机制:
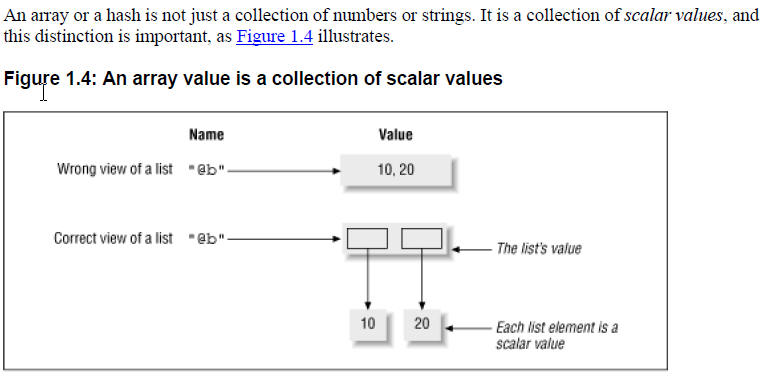
从上图知道,perl 的数组或者哈希,保存的不是数据或者字符,而是一个一个的标量变量(scalar)。
下面这句代码:
复制代码
由于perl数组机制与c数组储存机制不一样,perl数组是离散的。这样的话会定义500_000个标量变量。占用的内存会远大于C.
所以,如果不了解perl数组的内存机制,编代码的时候,就可能会出现程序提示out of memory错误,但却找不到原因。
一个100M的文件,大概是30多W的字符。如果一个数组来保存每个字符,perl就需要定义30多W的标量变量。这个规模有多大,可想而知。因此,我们写代码的时候,要特别注意数组的规模。避免是使用超大规模的数组,上面的例子可以用substr或者vec来解决问题
接下来再看一个例子:
如果我们想要做一个加法,计算1到5_000_000的总和。是否需要避免这么写:
复制代码
这样写是否合适,会否导致内存被大量使用。
答案是:
也就是说Perl5.005之前的版本会有这问题,5.005之后,for语句有了针对该现象的处理机制,所以可以放心在for循环里面放心使用range operate(范围操作符)。而不必去担心内存。
但是如果是在for循环外,如上面的@a=(1..5_000_000)这种语句还是要特别注意,尽量少用为妙。
我们读文件的时候,有时会这样写, 把文件内容都读入内存,以提高文件处理速度:
复制代码
但是,如果文件大小大于内存能够容纳的容量,那么装入内存后,不但不能提高代码运行速度,频繁的内存交换操作,反而会导致代码效率极低。
这个时候,我们应该选择用:
复制代码
什么是引用计数(reference count)?
简单的说,当建立一个变量(a)的时候,该变量(a)的引用计数置1。当其它变量(b)引用变量(a)的时候,引用计数+1.当引用该变量(b)失去对变量(a)的引用时,变量(a)的引用计数-1;当变量(a) 超出自身作用域的时候,变量(a)引用计数减1. perl将自动删除那些引用计数为0的变量的值。
举下面的例子来说明PERL是如何回收再利用的
复制代码
打印信息如下:
复制代码
地址0x869f72c被重用多次。具体工作状态如下:
第一次进入循环,$_为0:
my $tmp=123; 局部变量$tmp建立,对应地址0x869f72c,引用计数被设置为1.
my $addr=\$tmp; $tmp被$addr引用,引用计数+1,成为2.
$array[$_/2]=$addr; $tmp被$array[0]引用,引用计数成为3.
这个时候,第一次循环结束,$tmp和$addr超出作用域。所以对应的地址0x869f72c,引用计数减2。目前0x869f72c引用计数为1.
第二次进入循环,$_为1:
my $tmp=123; 局部变量$tmp建立,对应地址0x869eb44,引用计数被设置为1.
my $addr=\$tmp; $tmp被$addr引用,对应地址0x869eb44,引用计数+1,成为2.
$array[$_/2]=$addr; $tmp被$array[0]引用,对应地址0x869eb44,引用计数成为3.
这个时候,由于$array[0]原来的值(对地址0x869f72c的引用)被覆盖,所以地址0x869f72c的引用计数减1,地址0x869f72c的引用计数为0.PERL自动删除该地址的值。
第三次进入循环,$_为2:
my $tmp=123; 局部变量$tmp建立,对应地址0x869f72c,引用计数被设置为1.
地址0x869f72c被重新分配使用。
接着看看下面两个例子:
例1:
复制代码
为什么$r 和$s打印出来的结果一样,而$$r和$$s打印出来的结果却不一样呢?
例2:
复制代码
这个例子是否有错误呢:
例1其实是因为$s被字符化了,失去了引用的效果,那么,有没有办法通过字符化的变量$s,来找到$val的值呢?
例2其实会导致memory leak(内存泄露)。因为一直存在对自身的引用,所以该部分内存一直不会被释放
检查代码里面是否存在自引用,可以使用Devel::Cycle模块。
复制代码
那么,有没有办法直接证明这个写法存在内存泄露呢?
这里引出一个问题:退出了变量的作用域,那么我们如何去证明这个变量是否还存在。
也就是说我们必须去读内存数据,perl是否能够做到读取某一特定地址的值呢?
先介绍一个模块Devel::Peek,它可以打印出变量的具体信息。
比如下面这个例子:
复制代码
打印出来的结果如下:
复制代码
如果是字符串的话:
复制代码
打印出来的信息如下:
复制代码
解释上面的标示:
REFCNT就是该变量的引用计数。
FLAGS是。。。
perl有三种主要的数据类型:
SV Scalar Value
AV Array Value
HV Hash Value
这里就举标量变量的例子,因为array和hash到最后也是用scalar保存值的。
那么上面的IV(地址这些是代码表什么)
复制代码
perl保存数字的时候,会有两个地址,一个是IV(0x9cf77c0)还有一个是 0x9cdc6e4,那么这地址是什么关系呢?
其实,0x9cdc6e4地址的一开始4个字节,保存的就是:c0.77.cf.09。然后0x9cf77c0保存的才是值:11.
那么字符串变量的存储呢?
首先,地址0x957f6e4的前四字节保存的是:00.fb.57.09 ,也就是上面的PV(0x957fb00)
然后,地址0x957fb00的前四字节保存的是:c0.54.59.09 ,也就是0x95954c0这个地址。
最后,地址0x95954c0保存的才是: 31.32.33.34.61.62.63.64 ,也即是字符串内容:1234abcd
而在代码里面使用\$mem得到的地址是第一个地址。如第一个例子是:SCALAR(0x957f6e4),第二个例子是:SCALAR(0x957f6e4)
如果用这个地址来获取最终数值或者字符串的内容,那么将是挺麻烦的一件事情。
可以使用pack来解决这个问题,看下面的代码:
$a=pack( 'p', $mem);
printf ("%vx\n",$a);
打印出来的是:c0.54.59.09 ,也就是字符串保存的最终地址。
那么使用unpack('p',$a )来获取该地址的内容了。
'p'和'P'的区别可以看下:perldoc perlpacktut
既然已经找到PERL可以直接获取某一地址的内容的方法,那么我们就可以证明上面的代码存在内存泄露。
验证代码如下:
正常的代码:
复制代码
因为打印的时候,已经在@data1的作用域外,引用计数(referen count)为0,perl自动删除该变量。所以打印出乱码。
内存泄露的代码:
复制代码
可以看到,这里还能打印出won,也就是说数组@data1的内存并没被删除,这里就造成了内存泄露。
纠正方法1:退出作用域时,删除自引用。
复制代码
纠正方法2:
使用弱引用,Scalar::Util模块的weaken方法提供该功能,具体代码如下:
复制代码
之前遇到过这样一个问题:
QUOTE:
需求:
想要实现这么一个功能,现有一个字符串文件,比如说是有abcdefghijklmn,另外有一个文件是这样的信息:
5 e
7 g
11 k
前面一列是位置(从1开始记),后面是字符,我现在想验证这个文件这样的信息有多少是对的,多少是错的。
具体的做法:
把前面的字符串存到数组里,用下标做索引,然后通过这个数组来校验文件二。
主要实现代码入下:
my $a;
while (<>){
chomp;
$a .= $_;
}
my @a = split //, $a
当该代码在读取一个全是字符的100M大小的文件存到一个标量里,然后按空分开存到一
个数组里,为什么内存飞涨呢?大概要十几G的内存。
理论上是不需要这么多内存的啊?perl对此到底是如何分配内存的?
想要实现这么一个功能,现有一个字符串文件,比如说是有abcdefghijklmn,另外有一个文件是这样的信息:
5 e
7 g
11 k
前面一列是位置(从1开始记),后面是字符,我现在想验证这个文件这样的信息有多少是对的,多少是错的。
具体的做法:
把前面的字符串存到数组里,用下标做索引,然后通过这个数组来校验文件二。
主要实现代码入下:
my $a;
while (<>){
chomp;
$a .= $_;
}
my @a = split //, $a
当该代码在读取一个全是字符的100M大小的文件存到一个标量里,然后按空分开存到一
个数组里,为什么内存飞涨呢?大概要十几G的内存。
理论上是不需要这么多内存的啊?perl对此到底是如何分配内存的?
Perl数组的存放机制:
从上图知道,perl 的数组或者哈希,保存的不是数据或者字符,而是一个一个的标量变量(scalar)。
下面这句代码:
- @a=(1..500_000)
所以,如果不了解perl数组的内存机制,编代码的时候,就可能会出现程序提示out of memory错误,但却找不到原因。
一个100M的文件,大概是30多W的字符。如果一个数组来保存每个字符,perl就需要定义30多W的标量变量。这个规模有多大,可想而知。因此,我们写代码的时候,要特别注意数组的规模。避免是使用超大规模的数组,上面的例子可以用substr或者vec来解决问题
接下来再看一个例子:
如果我们想要做一个加法,计算1到5_000_000的总和。是否需要避免这么写:
- for(1..5_000_000){$i += $_;}
答案是:
QUOTE:
This situation has been fixed in Perl5.005. Use of ".." in a "for" loop will iterate over the range,
without creating the entire range.
without creating the entire range.
也就是说Perl5.005之前的版本会有这问题,5.005之后,for语句有了针对该现象的处理机制,所以可以放心在for循环里面放心使用range operate(范围操作符)。而不必去担心内存。
但是如果是在for循环外,如上面的@a=(1..5_000_000)这种语句还是要特别注意,尽量少用为妙。
我们读文件的时候,有时会这样写, 把文件内容都读入内存,以提高文件处理速度:
- Open F ,”path.txt ” or die “open file error : $!”;
- @content=<F>;
这个时候,我们应该选择用:
- Open F ,”path.txt ” or die “open file error : $!”;
- While(<F>){
- …..
- };
简单的说,当建立一个变量(a)的时候,该变量(a)的引用计数置1。当其它变量(b)引用变量(a)的时候,引用计数+1.当引用该变量(b)失去对变量(a)的引用时,变量(a)的引用计数-1;当变量(a) 超出自身作用域的时候,变量(a)引用计数减1. perl将自动删除那些引用计数为0的变量的值。
举下面的例子来说明PERL是如何回收再利用的
- my @array;
- for(0..10){
- my $tmp=123;
- my $addr=\$tmp;
- print "$_ get addr $addr\n";
- $array[$_/2]=$addr;
- }
- print "result: \n";
- print "$_\n" foreach(@array);
- 0 get addr SCALAR(0x869f72c)
- 1 get addr SCALAR(0x869eb44)
- 2 get addr SCALAR(0x869f72c)
- 3 get addr SCALAR(0x86e1640)
- 4 get addr SCALAR(0x869f72c)
- 5 get addr SCALAR(0x86e15f8)
- 6 get addr SCALAR(0x869f72c)
- 7 get addr SCALAR(0x86e1544)
- 8 get addr SCALAR(0x869f72c)
- 9 get addr SCALAR(0x86e1568)
- 10 get addr SCALAR(0x869f72c)
- result:
- SCALAR(0x869eb44)
- SCALAR(0x86e1640)
- SCALAR(0x86e15f8)
- SCALAR(0x86e1544)
- SCALAR(0x86e1568)
- SCALAR(0x869f72c)
第一次进入循环,$_为0:
my $tmp=123; 局部变量$tmp建立,对应地址0x869f72c,引用计数被设置为1.
my $addr=\$tmp; $tmp被$addr引用,引用计数+1,成为2.
$array[$_/2]=$addr; $tmp被$array[0]引用,引用计数成为3.
这个时候,第一次循环结束,$tmp和$addr超出作用域。所以对应的地址0x869f72c,引用计数减2。目前0x869f72c引用计数为1.
第二次进入循环,$_为1:
my $tmp=123; 局部变量$tmp建立,对应地址0x869eb44,引用计数被设置为1.
my $addr=\$tmp; $tmp被$addr引用,对应地址0x869eb44,引用计数+1,成为2.
$array[$_/2]=$addr; $tmp被$array[0]引用,对应地址0x869eb44,引用计数成为3.
这个时候,由于$array[0]原来的值(对地址0x869f72c的引用)被覆盖,所以地址0x869f72c的引用计数减1,地址0x869f72c的引用计数为0.PERL自动删除该地址的值。
第三次进入循环,$_为2:
my $tmp=123; 局部变量$tmp建立,对应地址0x869f72c,引用计数被设置为1.
地址0x869f72c被重新分配使用。
接着看看下面两个例子:
例1:
- my $val ="1234abc";
- $r =\$val;
- $s ="$r";
- print "\$r is $r \n";
- print "\$s is $s \n";
- print "\$\$r is $$r \n";
- print "\$\$s is $$s \n";
- 可以打印出1234abc.
- $r is SCALAR(0x8b106d8)
- $s is SCALAR(0x8b106d8)
- $$r is 1234abc
- $$s is
例2:
- {
- my @data1 = qw(one won);
- my @data2 = qw(two too to);
- push @data2, \@data1;
- push @data1, \@data2;
- }
例1其实是因为$s被字符化了,失去了引用的效果,那么,有没有办法通过字符化的变量$s,来找到$val的值呢?
例2其实会导致memory leak(内存泄露)。因为一直存在对自身的引用,所以该部分内存一直不会被释放
检查代码里面是否存在自引用,可以使用Devel::Cycle模块。
- use Devel::Cycle;
- {
- my @data1 = qw(one won);
- my @data2 = qw(two too to);
- push @data2, \@data1;
- push @data1, \@data2;
- find_cycle(\@data1);
- }
这里引出一个问题:退出了变量的作用域,那么我们如何去证明这个变量是否还存在。
也就是说我们必须去读内存数据,perl是否能够做到读取某一特定地址的值呢?
先介绍一个模块Devel::Peek,它可以打印出变量的具体信息。
比如下面这个例子:
- use Devel::Peek;
- my $mem=11;
- Dump($mem);
- SV = IV(0x9cf77c0) at 0x9cdc6e4
- REFCNT = 1
- FLAGS = (PADBUSY,PADMY,IOK,pIOK)
- IV = 11
- use Devel::Peek;
- my $mem="1234abcd";
- Dump($mem);
- SV = PV(0x957fb00) at 0x957f6e4
- REFCNT = 1
- FLAGS = (PADBUSY,PADMY,POK,pPOK)
- PV = 0x95954c0 "1234abcd"\0
- CUR = 8
- LEN = 12
REFCNT就是该变量的引用计数。
FLAGS是。。。
perl有三种主要的数据类型:
SV Scalar Value
AV Array Value
HV Hash Value
这里就举标量变量的例子,因为array和hash到最后也是用scalar保存值的。
那么上面的IV(地址这些是代码表什么)
- Working with SVs
- An SV can be created and loaded with one command. There are five types of values that can be loaded: an integer value (IV), an unsigned integer value (UV), a double (NV), a string (PV), and another scalar (SV).
- 还要加上,如果是 SV = RV(地址) ,RV是引用。
其实,0x9cdc6e4地址的一开始4个字节,保存的就是:c0.77.cf.09。然后0x9cf77c0保存的才是值:11.
那么字符串变量的存储呢?
首先,地址0x957f6e4的前四字节保存的是:00.fb.57.09 ,也就是上面的PV(0x957fb00)
然后,地址0x957fb00的前四字节保存的是:c0.54.59.09 ,也就是0x95954c0这个地址。
最后,地址0x95954c0保存的才是: 31.32.33.34.61.62.63.64 ,也即是字符串内容:1234abcd
而在代码里面使用\$mem得到的地址是第一个地址。如第一个例子是:SCALAR(0x957f6e4),第二个例子是:SCALAR(0x957f6e4)
如果用这个地址来获取最终数值或者字符串的内容,那么将是挺麻烦的一件事情。
可以使用pack来解决这个问题,看下面的代码:
$a=pack( 'p', $mem);
printf ("%vx\n",$a);
打印出来的是:c0.54.59.09 ,也就是字符串保存的最终地址。
那么使用unpack('p',$a )来获取该地址的内容了。
'p'和'P'的区别可以看下:perldoc perlpacktut
既然已经找到PERL可以直接获取某一地址的内容的方法,那么我们就可以证明上面的代码存在内存泄露。
验证代码如下:
正常的代码:
- my $a;
- {
- my @data1 = qw(one won);
- my @data2 = qw(two too to);
- $a=pack( 'p', $data1[1] );
- }
- print unpack('p',$a )."\n";
内存泄露的代码:
- my $a;
- {
- my @data1 = qw(one won);
- my @data2 = qw(two too to);
- $a=pack( 'p', $data1[1] );
- push @data2, \@data1;
- push @data1, \@data2;
- }
- print unpack('p',$a )."\n";
纠正方法1:退出作用域时,删除自引用。
- {
- my @data1 = qw(one won);
- my @data2 = qw(two too to);
- push @data2, \@data1;
- push @data1, \@data2;
- @data1=();
- @data1=();
- }
使用弱引用,Scalar::Util模块的weaken方法提供该功能,具体代码如下:
- use Scalar::Util qw/weaken/;
- {
- my @data1 = qw(one won);
- my @data2 = qw(two too to);
- push @data2, \@data1;
- push @data1, \@data2;
- weaken($data1[2]);
- weaken($data2[3]);
- }
作者: toniz 发布时间: 2010-10-08
此贴如此之“牛”,居然没有人顶?神马呀!
虽然我没有看,但是LZ也是流了汗水的呀,论坛里的人哪里去了?不厚道
我来顶
虽然我没有看,但是LZ也是流了汗水的呀,论坛里的人哪里去了?不厚道
我来顶
作者: brant_chen 发布时间: 2010-10-08

支持
作者: yybmsrs 发布时间: 2010-10-08
相关阅读 更多
热门阅读
-
 office 2019专业增强版最新2021版激活秘钥/序列号/激活码推荐 附激活工具
office 2019专业增强版最新2021版激活秘钥/序列号/激活码推荐 附激活工具
阅读:74
-
 如何安装mysql8.0
如何安装mysql8.0
阅读:31
-
 Word快速设置标题样式步骤详解
Word快速设置标题样式步骤详解
阅读:28
-
 20+道必知必会的Vue面试题(附答案解析)
20+道必知必会的Vue面试题(附答案解析)
阅读:37
-
 HTML如何制作表单
HTML如何制作表单
阅读:22
-
 百词斩可以改天数吗?当然可以,4个步骤轻松修改天数!
百词斩可以改天数吗?当然可以,4个步骤轻松修改天数!
阅读:31
-
 ET文件格式和XLS格式文件之间如何转化?
ET文件格式和XLS格式文件之间如何转化?
阅读:24
-
 react和vue的区别及优缺点是什么
react和vue的区别及优缺点是什么
阅读:121
-
 支付宝人脸识别如何关闭?
支付宝人脸识别如何关闭?
阅读:21
-
 腾讯微云怎么修改照片或视频备份路径?
腾讯微云怎么修改照片或视频备份路径?
阅读:28