
FFT in GPU
时间:2014-05-01
来源:互联网
而CooleyTukey这类FFT算法....偏偏就系大量使用recursion的算法
所以在设计GPU专用的FFT算法时通常会有很多问题
所以...汪汪就做左一D改进...
把CooleyTukey变成looping方式(但在GPU上还是不能用looping来做...之后解释)
首先
CooleyTukey算法原本为recursion算法...
要改成looping方式就要找出recursion的中心点(Fixed-point位置)
而CooleyTukey算法的中心点就在重排资料和把复数相加之间
1. 资料以单数项(odd)和双数项(even)分成两block data
2. 计算出CooleyTukey(odd)和CooleyTukey(even) ...这里就是recursion的中心点
3. 把第二步的结果相加
以recursion的中心点为中心....把中心点以上的算式改成顺序的looping
而中心点以下的算式改成倒序的looping
CooleyTukey算法的中心点以上的顺序looping部分...
汪汪找到方法可以化简...变成简化版的资料排序算法
{
size_t level = m;
size_t _idx = idx[0];
size_t _level = level;
size_t i = 0;
while (_level >>= 1)
{
i += (_idx < _level ? 0 : (level / _level) >> 1);
_idx %= _level;
}
_temp[idx]._Val[0] = _a[i];
_temp[idx]._Val[1] = 0;
_temp[idx]._Val[0] /= sqrt((float)m);
_temp[idx]._Val[1] /= sqrt((float)m);
});
汪汪用function包起来
在这里解释点解唔用looping..而系hard code黎做
因为GPU的资料读取...其中一个方法系以块的形式来处理
但如果要使用块状处理资料....就一定要使用compile time const的looping方法
即下面段code的_a.extent.tile和tiled_index的模板常数
结果就限制左...必须要hard code完成
不过...其实如果唔用GPU的块状data功能...
也可以改成真正的looping
{
GP(t_idx, _temp);
});
parallel_for_each(_a.extent.tile<4>(), [=](tiled_index<4> t_idx) restrict(amp)
{
GP(t_idx, _temp);
});
parallel_for_each(_a.extent.tile<8>(), [=](tiled_index<8> t_idx) restrict(amp)
{
GP(t_idx, _temp);
});
parallel_for_each(_a.extent.tile<16>(), [=](tiled_index<16> t_idx) restrict(amp)
{
GP(t_idx, _temp);
});
parallel_for_each(_a.extent.tile<32>(), [=](tiled_index<32> t_idx) restrict(amp)
{
GP(t_idx, _temp);
});
parallel_for_each(_a.extent.tile<64>(), [=](tiled_index<64> t_idx) restrict(amp)
{
GP(t_idx, _temp);
});
void GP(tiled_index<level> t_idx, array_view<complex<float>, 1> _temp) restrict(amp)
{
tile_static complex<float> _t[level];
_t[t_idx.local[0]]._Val[0] = _temp[t_idx]._Val[0];
_t[t_idx.local[0]]._Val[1] = _temp[t_idx]._Val[1];
t_idx.barrier.wait();
size_t _halflength = level >> 1, i = t_idx.local[0] % _halflength;
float _angle = -(float)M_PI * (float)i / (float)_halflength;
float _cos = cos(_angle), _sin = sin(_angle);
float _Real = _cos * _t[i + _halflength]._Val[0] - _sin * _t[i + _halflength]._Val[1];
float _Imag = _cos * _t[i + _halflength]._Val[1] + _sin * _t[i + _halflength]._Val[0];
if (t_idx.local[0] < _halflength)
{
_temp[t_idx]._Val[0] = _t[i]._Val[0] + _Real;
_temp[t_idx]._Val[1] = _t[i]._Val[1] + _Imag;
} else
{
_temp[t_idx]._Val[0] = _t[i]._Val[0] - _Real;
_temp[t_idx]._Val[1] = _t[i]._Val[1] - _Imag;
}
}
作者: Susan﹏汪汪 发布时间: 2014-05-01
下面第一张图系Visual Studio上执行结果
以1024 length的data做1000次FFT运算
GPU计算需要时间为1.2秒

而CPU计算时间为1.8秒
而第二张图就系在真实执行环境...
GPU计算需要时间为1.0秒
而CPU计算时间为0.66秒
明显CPU运算会严重受Visual Studio的模拟器影向
但GPU运算都未发挥到水准

2014-4-17 11:58 PM
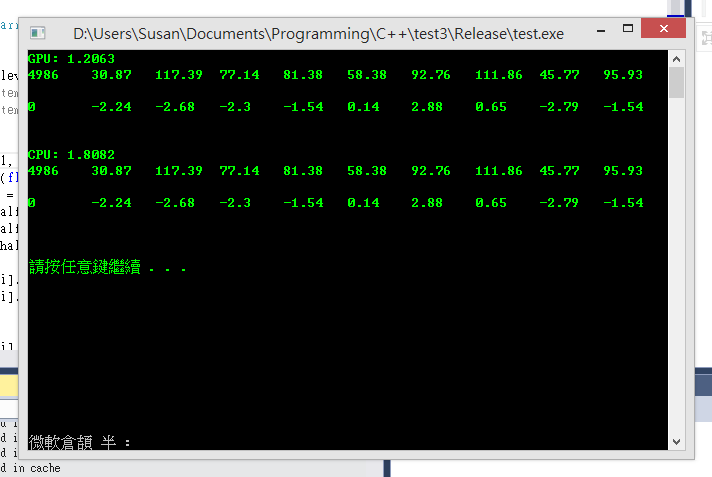
2014-4-17 11:58 PM
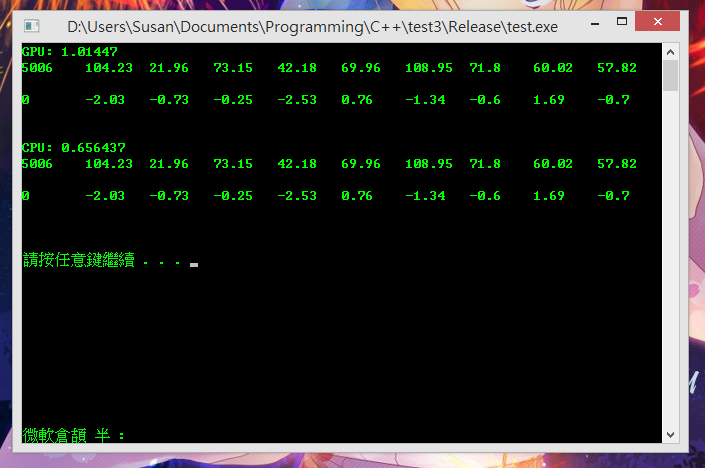
2014-4-17 11:58 PM
2014-4-17 11:58 PM
作者: Susan﹏汪汪 发布时间: 2014-05-01
结果如下图
如果以VS环境下执行
CPU同样会严重受VS模拟器影向...但GPU则近乎不受影向地运作
[ 本帖最后由 Susan﹏汪汪 於 2014-4-18 12:36 AM 编辑 ]
2014-4-18 12:26 AM
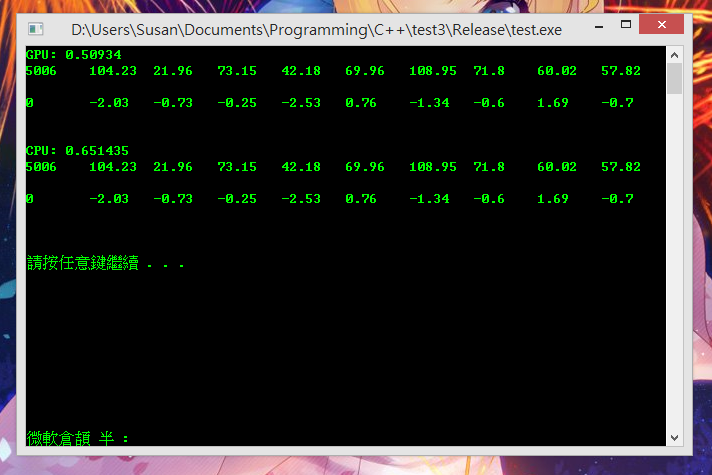
2014-4-18 12:26 AM
作者: Susan﹏汪汪 发布时间: 2014-05-01
N card 本身的架构又有分 Global memory, share memory, 有严格的使用方法, 而 AMP 有无呢 d 野? 如果无, 咁真系唔知佢当中有无野 warp 得唔好, 搞到出问题

作者: 烟民比食屎9更贱 发布时间: 2014-05-01
好明显有问题啦! 即使要 main memory copy 去 gpu ram, 都无可能差咁少! 应该至少 1 倍以上的! 以 N card 为例, Streaming Multiprocessor 已可容纳 768 条 thread, 无可能会连1 倍都快唔过 cpu!
N card 本身的架 ...
因为1024个data还是好少
以计算FFT来看...1024个data可能得果1毫秒 (所以汪汪先会重覆计算1000次来放大时间值)
以呢种角度看...
GPU和CPU计算单次所需时间得果1毫秒的话...实验的时间误差所占的比例非常可观(例如CPU的copy速度)
而计算1000次除左放大需要作比较的GPU和CPU时间值外...还会同时放大实验误差
但问题系...VS而家只容许最多一次过建立长1024个data的tile
所以未修改算法都未可作准...要等再做一次实验先可以(例如把data增长至131072)
[ 本帖最后由 Susan﹏汪汪 於 2014-4-18 01:36 AM 编辑 ]
作者: Susan﹏汪汪 发布时间: 2014-05-01
作者: 烟民比食屎9更贱 发布时间: 2014-05-01
总之无可能差咁少! 用 gpu 计野, 以 1 倍至几十倍不等
CPU和GPU计算1024个data的FFT都可能只有1毫秒
而量度时间的最高准确度也只有1毫秒
所以最终能够测量的最小值都系1毫秒
咁得出的实验结果时间咪差不多lor

作者: Susan﹏汪汪 发布时间: 2014-05-01
热门阅读
-
 office 2019专业增强版最新2021版激活秘钥/序列号/激活码推荐 附激活工具
office 2019专业增强版最新2021版激活秘钥/序列号/激活码推荐 附激活工具
阅读:74
-
 如何安装mysql8.0
如何安装mysql8.0
阅读:31
-
 Word快速设置标题样式步骤详解
Word快速设置标题样式步骤详解
阅读:28
-
 20+道必知必会的Vue面试题(附答案解析)
20+道必知必会的Vue面试题(附答案解析)
阅读:37
-
 HTML如何制作表单
HTML如何制作表单
阅读:22
-
 百词斩可以改天数吗?当然可以,4个步骤轻松修改天数!
百词斩可以改天数吗?当然可以,4个步骤轻松修改天数!
阅读:31
-
 ET文件格式和XLS格式文件之间如何转化?
ET文件格式和XLS格式文件之间如何转化?
阅读:24
-
 react和vue的区别及优缺点是什么
react和vue的区别及优缺点是什么
阅读:121
-
 支付宝人脸识别如何关闭?
支付宝人脸识别如何关闭?
阅读:21
-
 腾讯微云怎么修改照片或视频备份路径?
腾讯微云怎么修改照片或视频备份路径?
阅读:28