
MySQL 加快 update 速度
时间:2014-05-15
来源:互联网
update table1 as a, table1 as b set b.flag3='Y' where a.flag3='Y' and a.connection=b.connection and and a.employee_id=b.employee_id and b.flag3='N' and b.flag2='DD' and b.flag1 like 'BB%' and b.connection>='2014-03-01'
同一组我想搵出来既会有两条 record, 个 connection time 会系一样, 其余 flag1, flag2, flag3 唔一样, 但由於其他 employee_id 亦有机会产生任何 connection time 既 record, 所以我用左 table1 self join 形式去搵相关 record 出来.
但发觉速度好慢, 要用一粒钟先行完, 请问有冇方法改动一下可以加快速度呢? 唔该晒.
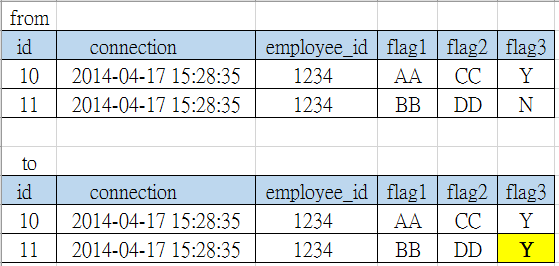
作者: barca883 发布时间: 2014-05-15
作者: McLoneIII 发布时间: 2014-05-15
`id` int(11) NOT NULL AUTO_INCREMENT,
...
PRIMARY KEY (`id`)
还是做得未够? Thanks.
作者: barca883 发布时间: 2014-05-15
加左:
`id` int(11) NOT NULL AUTO_INCREMENT,
...
PRIMARY KEY (`id`)
还是做得未够? Thanks.
一个系indexing,一个系sql statement structure
indexing唔系只系index id field
而系indexing成日filter既columns.
例如你既sql statement成日filter flag2 (flag2='DD'),你就应该index flag2
记住唔好index所有columns,太多index都会减低performance
第二,sql statement structure
我唔系MySQL人,我系Oracle人,但都系shares同一道理
当database executes sql statement时
有时将容易filter既clause放系前面会增加performance
作者: McLoneIII 发布时间: 2014-05-15
另外, 要避免 index 过多引致反效果, 通常会以乜野准则衡量呢? indexed column 占全部 column 数目的百份比? 唔该晒.
作者: barca883 发布时间: 2014-05-15
我 index 多 6 个相关 column, 再行多次, 结果唔使 10 秒就行完, 计落快左几百倍! 真系唔该晒.
另外, 要避免 index 过多引致反效果, 通常会以乜野准则衡量呢? indexed column 占全部 column 数目的百份比? 唔该晒 ...
即系当你一个table太多indexing,虽然select时会快,但insert/modify/delete时会慢。
indexing既基本知识系,如果table无performance problem,唔洗加index。
如果有performance problem,要睇下有问题既sql statement入面有乜野select clauses.
而select clauses入面边个引至performance problem
有D情况indexing唔会帮助select statement既performance,例如value like '%abc%'
因为indexing只会index头/尾/整个value,而唔会index中间D value (It's how Oracle works. I am not sure about MySql).
如果要indexing头/尾几个字,要自己custom indexing algorithm.
以你个case,如果你唔识custom indexing,你唔洗index
flag1 (b.flag1 like 'BB%').
indexed column无乜野话几多百份比,而系以分析有问题既sql statement为解决问题
衡量准则..... 唔... 除左我之前所讲,仲有好睇经验,有时要case by case based.
作者: McLoneIII 发布时间: 2014-05-15

作者: 烟民比食屎9更贱 发布时间: 2014-05-15
作者: nov012006 发布时间: 2014-05-15
其实你个CASE, 加个INDEX系 CONNECTION + employee_id 可能已经解决问题.
作者: McLoneIII 发布时间: 2014-05-15
所谓 index 都系靠 sql server 的纪录在另一个table 的统计, 以此作为 "靠估" 的基准
作者: TritonHo 发布时间: 2014-05-15
热门阅读
-
 office 2019专业增强版最新2021版激活秘钥/序列号/激活码推荐 附激活工具
office 2019专业增强版最新2021版激活秘钥/序列号/激活码推荐 附激活工具
阅读:74
-
 如何安装mysql8.0
如何安装mysql8.0
阅读:31
-
 Word快速设置标题样式步骤详解
Word快速设置标题样式步骤详解
阅读:28
-
 20+道必知必会的Vue面试题(附答案解析)
20+道必知必会的Vue面试题(附答案解析)
阅读:37
-
 HTML如何制作表单
HTML如何制作表单
阅读:22
-
 百词斩可以改天数吗?当然可以,4个步骤轻松修改天数!
百词斩可以改天数吗?当然可以,4个步骤轻松修改天数!
阅读:31
-
 ET文件格式和XLS格式文件之间如何转化?
ET文件格式和XLS格式文件之间如何转化?
阅读:24
-
 react和vue的区别及优缺点是什么
react和vue的区别及优缺点是什么
阅读:121
-
 支付宝人脸识别如何关闭?
支付宝人脸识别如何关闭?
阅读:21
-
 腾讯微云怎么修改照片或视频备份路径?
腾讯微云怎么修改照片或视频备份路径?
阅读:28